

Proof-Of-Work (For Dummies!)
Proof-Of-Work (For Dummies!)
The year is 1997. The internet is growing at a mind-blowing pace. It’s a glorious time to be alive.
But, while man rapidly builds his greatest invention, a few bad actors are quietly plotting to screw it all up.
They want to abuse the reach and accessibility of the internet by flooding it with unsolicited promotional emails - “spam,” as the youths call it.
And in 1997, inboxes everywhere agree: the spammers are winning.
Why do people send spam?
Most spam either tries to sell something (advertising) or trick a user into sharing sensitive information (phishing) that the sender can use maliciously.
Why is it so easy to send spam emails?
An individual email is a tiny file that can be reproduced and distributed near-instantaneously to millions of people at essentially no cost (relative to the next best options).
Sending email is cheap mostly because:
The distribution channel (the internet) is essentially free and open to anybody
It requires negligible compute resources to send an email
The first fact, at least in 1997, was impractical to change.

The second was far more negotiable.
What if our email protocols required a computer to exert some modest computational effort in order to send a message?
Sending a single email wouldn’t be overly-demanding (perhaps only taking a second or so), but sending millions upon millions would quickly become a Herculean effort requiring massive, and therefore expensive, compute resources.
This gave birth to proof-of-work systems.
In a proof-of-work system, a computer is required to solve a computational problem of a pre-determined level of difficulty before it’s allowed to take some desired action.
Once the computer solves the problem, it shares its answer as “proof” of its efforts.
Another computer is able to quickly verify the proof and allow the desired action to take place.
In the case of limiting spam, we’d want our email client to only accept an email from somebody who has provided proof they underwent an effort to get it to us.

So, how can we verify that a computer has made a particular effort?
Imagine we have a function that, for any given input, produces a fixed-size output.
Pretty simple.
When we send a simple string through our function:
our_function(“Which one of you bastards ate my pad thai?”)
It returns:
'd6b1f2b59a73a93fb62ec75ee5df121f7717a8a757cd15c35bbc20ae8e810379'
It produces this output every time we send that exact string through it.
Now, take a look at what happens when we change one single character in our input:
our_function(“Which one of you bastards ate my pad thai!”)
Returns:'41c4f3e63c45f8cdf7fcd46d32eddbf8bf51bd656919b68ec50d226ca36a951b'
The output is radically different!
This makes it impractical to reverse-engineer how input is transformed into output. Tiny alterations to our input do not create obvious, measurable changes to the output.
Also, remember that our output is always a string of a fixed size. In this example, our output will always be 64 characters long.
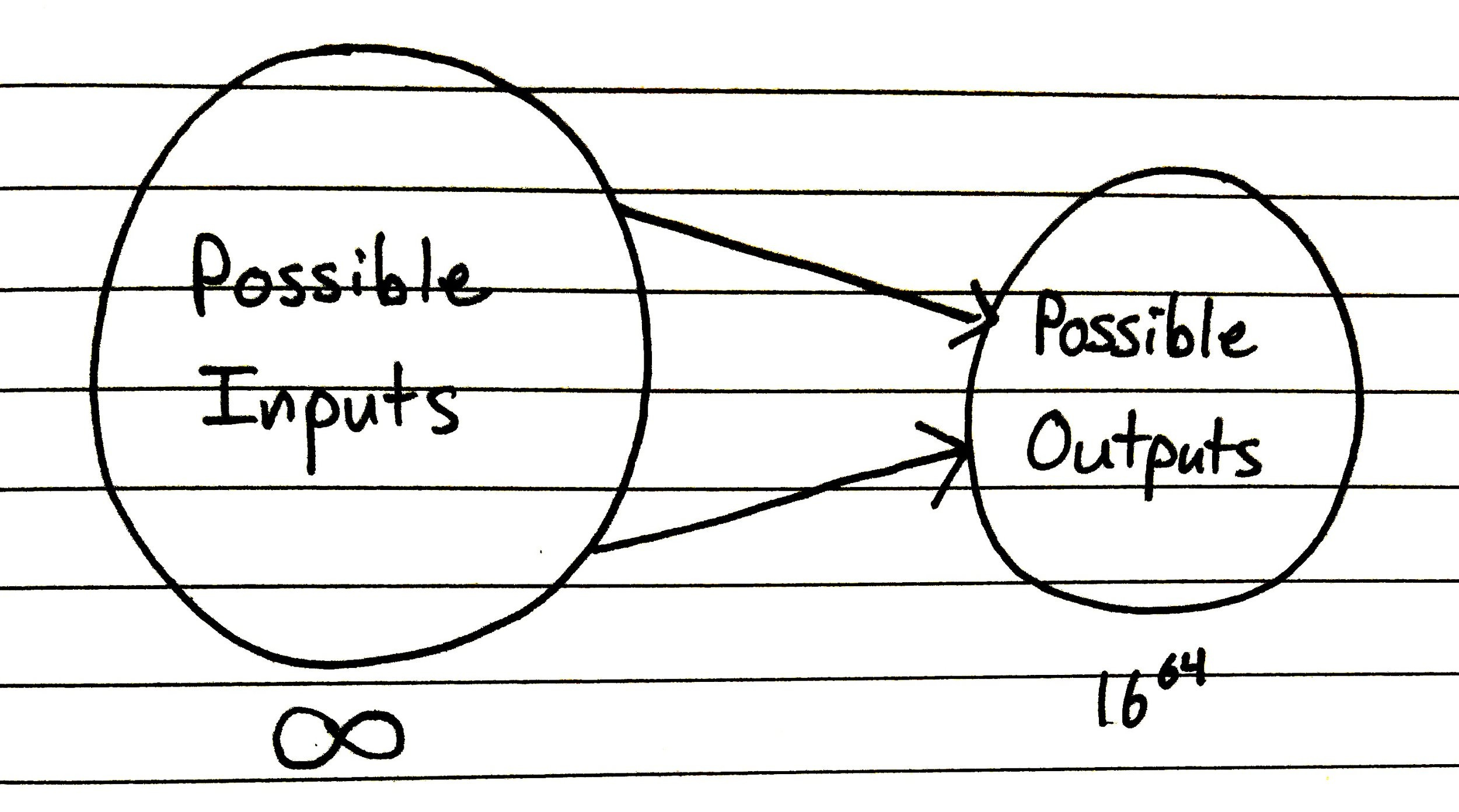
For simplicity, let’s imagine that every character in the output string can only be one of the 16 hexadecimal values (0-9, a-f). Even with these constraints, our function yields an enormous number of possible outputs.
A math refresher: a 64 character-long string where each character can be one of 16 items produces 1664 different possible outputs. 1664 is a ludicrously large number. Like, total-atoms-in-the-observable-universe huge.
Given the enormous range of possible output values, we will be able to generate a unique output string for pretty much any input.
Occasionally, two different inputs will map to the same value (a “collision”), but in our function this is extremely rare.
Put simply: our function creates a unique identifier for almost any unique input.
There’s a fancy name for the type of function we just built: a “cryptographic hash function.”
Cryptographic hash functions have a few other properties, but our example covers the most relevant. So…
How can we use this function to "prove" a computer has done some work?
Recall that our function executes quickly. It's not hard to run some input through and produce some output.
But, imagine if we asked:
Solve for an input, n, where our_function(n) returns the following output: ‘0c756ce63af37a723cf4f8012f6817a58ba55196bf0f9dc9f962086d24f6ab7f’.
Assuming the computer had never seen the particular output string (and had known the input that produced it), it would have to start making random guesses and checking the output.
But, remember, it could take up to 16^64 guesses to get the right answer. [1]
That could literally take billions of years to solve, so instead we might ask a far less demanding question like:
Solve for an input, n, where our_function(n) returns an output where the first three characters are 0’s.

Assuming we hadn’t worked with our_function(n) in the past, we would start making random guesses until we received an output like:
‘000a58ba55196bf0f56ce63af37a723cf4f8012f68179dc9f962086d24f6ab7f’
It requires dramatically less effort to guess three correct characters than 64.
If we wanted to make things more challenging, we’d go from matching the first 3 characters to matching the first 4, then the first 5. Each step becomes 16 times more difficult than the last because, recall, there are 16 possible values for each character.
We can think of this as a work factor. We'd like the ability to make problems harder over time if needed. After all, any challenge we would have created in 1997 would be trivially easy to complete today with our faster processors.
We still have a problem though: once somebody has found an input that produces a desired output, they can just re-use the answer the next time they’re asked the same question, exerting negligible effort.
So, to prevent re-using answers, we could generate a random value each time we ask the question and require that it be appended to the input, thereby guaranteeing that they couldn't re-use an old answer (remember: altering just one character to our input dramatically alters the output).
Our question would look more like:
Given a random string, solve for an input, n, where our_function(n + random_string) returns an output where the first three characters are 0’s.
random_string= ‘a562e1L’
Even if they discovered an input, n, that had previously produced an output starting with three 0’s, that same input n combined with a random string would produce a wildly different value, requiring them to start from scratch and solve for a different n.
Now, obviously, our random string generation function would need to be truly random. A half-assed random generator that produced the same challenges more frequently than pure probability would increase the likelihood of a challenger receiving the same challenge twice.
But, that's a rabbit hole for another day.
Putting this all together, a simple function to guess the value of n might look like the following:
In the code above, "challenge" is the random string that we'll send to a challenger.
And we might validate random guesses for n with something like this. We're just asking if Hash(n + random_string) outputs a value that starts with a sufficient number of 0's.
Pretty simple, huh?
There are a few more things we'll need to build out to make this sensible, particularly for the concepts invented for combatting spam (Hashcash, in particular), but hopefully this illustrates the underlying theory behind proof-of-work.
- Stew
[1] Which, for the curious, is: "All of you have broken the sacred bond of office refrigerator trust."